RANK(), DENSE_RANK(), ROW_NUMBER() 는 셋 다 순서에 따라 랭킹을 만들어 주는 함수입니다.
1. RANK( )
사용법
RANK() OVER (ORDER BY column_name DESC/ASC)
> 특징
- 동일한 값이 있을 때 같은 순위를 할당하고 중간 순위를 건너뜁니다.
- 중복된 값이 있을 경우, 같은 순위를 가지게 됩니다.
RANK() 뒤에 OVER 다음에 나오는 괄호에 안에 출력하고 싶은 데이터를 정렬하는 SQL 문장을 넣으면 그 컬럼 값에 대한 데이터의 순위가 출력됩니다. 또한 오름차순, 또는 내림차순에 대한 옵션을 사용자가 설정할 수 있습니다.
2. DENSE_RANK( )
사용법
DENSE_RANK() OVER (ORDER BY column_name DESC/ASC)
> 특징
- 중복된 값이 있어도 중간 순위를 건너뛰지 않고 순차적인 순위를 할당합니다.
- 중복된 값이 있을 경우, 같은 순위를 가지게 됩니다.
데이터의 순위를 상세하게 출력하기 위해서 DENSE_RANK 함수를 사용합니다.
3. ROW_NUMBER( )
사용법
ROW_NUMBER() OVER (ORDER BY column_name)
> 특징
- 각 행에 고유한 숫자를 할당합니다.
- 중복된 값이 있더라도 항상 고유한 값을 할당합니다.
예제
- member 테이블에서 각 회원의 이름(mem_name)과 키(height)에 따른 순위를 계산
SELECT mem_name,
height,
RANK() OVER(ORDER BY height DESC) AS 'RANK',
DENSE_RANK() OVER(ORDER BY height DESC) AS 'DENSE_RANK',
ROW_NUMBER() OVER(ORDER BY height DESC) AS 'ROW_NUMBER'
FROM member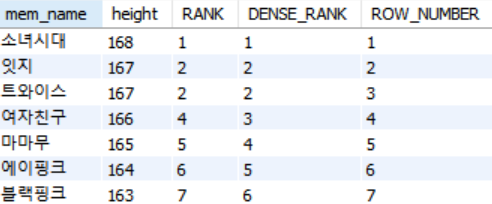
결과를 살펴보면 RANK(), DENSE_RANK(), ROW_NUMBER() 함수 각각의 동작 방식을 쉽게 확인할 수 있습니다.
- RANK() : 2위가 두 명이 동시에 같은 순위를 가지고 있으므로 그 다음 순위인 3위는 건너뛰고 4위로 할당되었습니다.
- DENSE_RANK() : 중복된 순위 2위가 있더라도 중간 순위를 건너뛰지 않고 연속적인 순위가 부여되었습니다.
- ROW_NUMBER() : 중복된 값이 있더라도 2위, 3위로 각 행에 고유한 번호가 부여되었습니다.
4. PARTITION_BY
PARTITION BY 절을 사용하면 RANK(), DENSE_RANK(), ROW_NUMBER() 함수를 더 세분화하여 그룹별로 순위를 할당할 수 있습니다. 이를 통해 그룹별로 나누어 각 그룹 내에서 순위를 매길 수 있습니다.
SELECT addr,
height,
RANK() OVER(PARTITION BY addr ORDER BY height DESC) AS 'RANK',
DENSE_RANK() OVER(PARTITION BY addr ORDER BY height DESC) AS 'DENSE_RANK',
ROW_NUMBER() OVER(PARTITION BY addr ORDER BY height DESC) AS 'ROW_NUMBER'
FROM member
ORDER BY addr
=> 위의 쿼리는 member 테이블에서 주소(addr)별로 그룹을 만들어 각 그룹 내에서 회원들의 키(height)에 따른 순위를 계산합니다.
정리하자면 세 함수는,
- RANK(): 동일한 값에 대해 같은 순위가 필요한 경우에 사용됩니다.
- DENSE_RANK(): 중복된 값에 상관 없이 연속적인 순위가 필요한 경우에 사용됩니다.
- ROW_NUMBER(): 각 행을 유일하게 식별하고 싶을 때 사용됩니다.
이렇게 순위 함수를 사용하면 데이터의 순서에 따라 순위를 계산할 수 있습니다. 각 함수는 데이터의 특성에 따라 적합한 순위 계산 방식을 제공하므로, 사용 시에 주의하여 선택해야 합니다.
'Skills > SQL' 카테고리의 다른 글
| [프로그래머스] SQL - '특정 세대의 대장균 찾기' 문제풀이 (0) | 2024.04.29 |
|---|---|
| [SQL] 등급 매기기 함수 : NTILE (0) | 2024.04.25 |
| [프로그래머스] SQL - '연간 평가점수에 해당하는 평가 등급 및 성과금 조회하기' 문제풀이 (0) | 2024.04.23 |
| [프로그래머스] SQL - '대장균의 크기에 따라 분류하기 2' 문제풀이 (0) | 2024.04.22 |
| [프로그래머스] SQL - '특정 조건을 만족하는 물고기별 수와 최대 길이 구하기' 문제풀이 (0) | 2024.04.20 |



